95% betrouwbaarheidsinterval categoriale variabele.
Excel kent alleen voor variabelen op kwantitatief niveau (scale) een functie voor het berekenen van het betrouwbaarheidsinterval .
Het betrouwbaarheidsinterval is gebaseerd op de standaardschattingsfout.
Voor een categoriale variabele is de standaardschattingsfout:
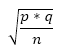
De frequentietabel van de variabele Geslacht in de dataset DataWoonwensenStudenten is:
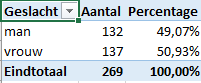
P=49%
q=(100%-49%)=51%
n= 132+137=269
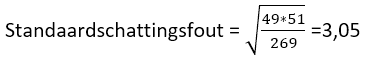
Ondergrens mannen 49%-2*3,05=42,9
Bovengrens mannen 49%+2*3,05=55,1
We kunnen dus met 95% zekerheid zeggen dat het percentage mannen van de populatie zit in het interval [42,9 ; 55,1]
In Excel berekenen we dit als volgt:
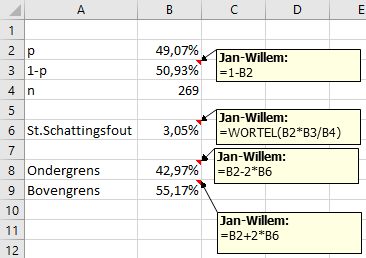
Uitleg: De waarde p 49,07% haal je uit de tabel.
q=(1-p)
ofwel in Excel de formule "1-B2"
n is het aantal (Direct uit tabel af te lezen).
De st.schattingsfout is dan direct te berekenen met de formule "=WORTEL(B2*B3/B4)
De onder en bovengrens zijn te berekenen door bij p + of - tweemaal de standaarschattingsfout op te tellen.
Stel we willen weten wat het 95% betrouwbaarheidsinterval van die studenten die minder dan 10 min. reistijd hebben, dan berekenen we dit als volgt:
De frequentietabel van de variabele Reistijd is:
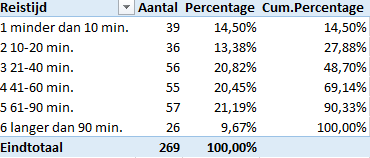
In Excelblad invullen 14,50% i.p.v. 49,07%
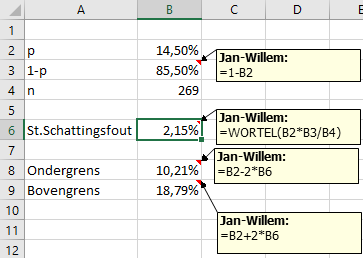
Het 95% betrouwbaarheidsinterval is: [10,21% ; 18,79%]